Machine
Learning Everywhere for Advanced Computing Systems Concept PaperCore References
1.
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram
Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe,
Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, "Learning Everywhere:
Pervasive Machine Learning for Effective High-Performance Computation", to be presented at HPBDC 2019,
The 5th IEEE International Workshop on High-Performance Big Data, Deep
Learning, and Cloud Computing in conjunction with The 33rd IEEE International
Parallel and Distributed Processing Symposium (IPDPS 2019) Rio de Janeiro,
Brazil, May 20th, 2019.
2.
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram
Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe,
Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, "Learning Everywhere:
Pervasive Machine Learning for Effective High-Performance Computation:
Application Background", Technical Report
February 16 2019.
Technical Summary
The essential idea is that Machine Learning can dramatically improve large scale computing performance by embedding ML in all aspects of the system execution. This has been demonstrated in several exemplars but not systematically explored from an application or hardware and software systems point of view. We propose an innovative environment with new hardware and software supporting the dynamic flexible interlinking of ML and computation where the latter could either be large scale simulations or data analytics. The environment must support algorithms, hardware and applications. We address the use of ML to optimize configurations and execution modes (MLAutotuning) [1-6], as well for learning the results of all or parts of the computation (MLaroundHPC). At the same time, the system must exhibit HPCforML [7-12] i.e. the machine learning runs fast, to obtain timely results and to minimize overhead for the main computation. All of these new execution modes promise major increases in both performance (inference is many orders of magnitude faster than simulation) and productivity, as they do not require changing existing codes but rather integrate learning with all system aspects, from low-level networking and operating systems to high-level algorithms.
The goal of “learning everywhere” [13] means that we have to make it extremely convenient to add learning to all types of existing software. Our software approach is built around a high-performance environment, “data-linked functions as a service,” that extends dataflow and fully supports the dynamic intermingling of computation and learning and the transfer of data between them. Machine Learning Everywhere also implies extensive research into learning algorithms effective across different uses of MLaroundHPC and their uncertainty quantification.
For the hardware, we need to study appropriate accelerators (both existing accelerators and proposing new ones) and the memory-storage architecture to support the extensive data processing between the learning and computation modules. In particular, we will seek to develop a heterogeneous architecture with accelerators that can be retargeted to support both computation and ML.
Because many of these tasks (both the applications and the ML) are extremely data-intensive, it will be of particular importance to design accelerators that minimize data movement overheads, either by pipelining memory accesses and
computation, or by tightly coupling computation with the data (via processing-in-memory, die stacking, or other methods of tight physical and architectural integration).
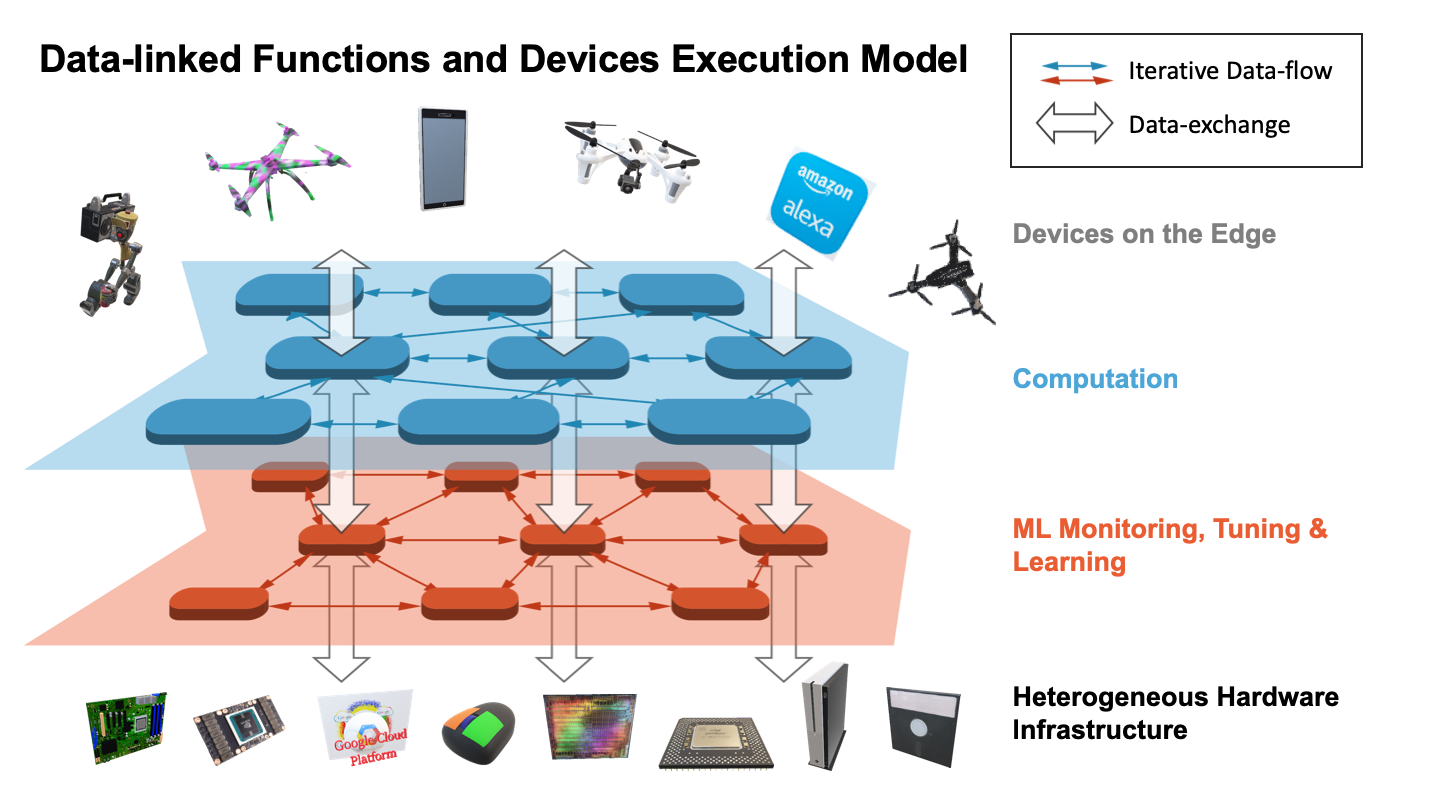
These
software, algorithm, hardware challenges [14-16] need to be motivated and
tested in state of the art applications.
One can expect this approach to have different success and different
challenges in different applications and in this initial study, we hope to get
insight into this using two large-scale network-science problems that are
important in DoD missions. Problems that we will consider include: (i) finding motifs and counting motifs in large
irregular networks, and (ii) simulating
the contagion process. For the contagion simulations, we will build on a long
history in developing scalable simulations where we have already run on
machines with over 700,000 cores. Similarly,
our recent work on computing network motifs represents a factor of 10 improvement over the state of the art methods.
Efficient parallel computing has special difficulties with ML-assisted
computations due to the very different execution times for surrogate (much
smaller) and fully computed results. A further challenge is that heterogeneous architectures
often create a tradeoff between computing where the data currently resides,
using a processor that is not ideally matched to the task, versus moving data
to the most suitable processor. This will need new approaches to load balancing
and new techniques in modeling performance and scaling.
The
“processor suitability” question also motivates reconfigurable architectures
where we will research near-data processor architectures prototyped on FPGAs
with high-bandwidth memory.
Impact: Initial results suggest that effective
performance increases from ML-assisted simulations are broadly based and large
(105 in one example) and this approach can lead to effective
zettascale performance when executed on the upcoming exascale-class systems. So
far we have studied molecular simulations (at the nano and biomolecular
scales), virtual tissue and cellular simulations, and socio-technical problems
such as modeling the spread of disease and epidemics. For these simulations,
one can learn dynamic step sizes in space and time and design a principled
approach to coarse-graining which appears in the many multi-scale problems we
need to study. Examples for data analytics include an influential paper on
learning index structures from the data and so outperforming general
approaches. Initial results are very promising and
our proposed research will allow the application domains to be greatly
accelerated and expanded so that these performance gains and impact will cover
a broad range of problems; academic, commercial,
and national security. This major impact implies that it is critical to immediately start significant activities in
Learning Everywhere. Some of the initial studies and experience should
open up major new questions on how to use ML and design supporting computer
systems that will need deeper study. As well as the core hardware and software
challenges, the issues of systematizing coarse-graining, and uncertainty
quantification, are just some examples of issues waiting to explode with
interest.
Programmatic: The team involves researchers
from Indiana University, Rutgers, and Virginia. The team already has very
effective collaboration built up by multiple joint NSF grants over the last 5
years. Our expertise covers systems hardware,
software, algorithms, and applications and we will use an
algorithmic-systems-hardware codesign process. We will demonstrate initial work
on small clusters exhibiting the key
storage/memory (such as NVMe and Intel Optane or equivalent) and accelerator
(GPU, vector, neuromorphic, FPGA) characteristics. The lead PI will be Geoffrey
Fox from Indiana University, who has experience in the key areas. The software
will be based on an existing high-performance dataflow system Twister2 that was
recently released. The systems work will be covered by Rutgers (Jha) and
Indiana University (Fox, Qiu), and
Virginia University will lead the hardware (Skadron) and the socio-technical
simulations (Marathe, Barrett). Funding requested is $1.5M a year.
Deliverable Timeline
Year 1
Initial software environment running
on small customized cluster tested with basic disease applications. Also tested
on larger generic clusters with GPUs and with FPGAs, potentially using cloud
resources such as Amazon’s F1. Initial research on uncertainty quantification
and coarse-graining. Workshop held at the end of the year will identify new
applications. Initial application focus on subtree mining and contagion spread.
Year 2
Year one work extended including a
larger customized cluster. Initial testing of coarse-graining and uncertainty
quantification. Major upgrade to software to enhance usability by a broad
community. Applications add the study of tree-like patterns in a general graph.
Powerful performance and scaling model. Workshop held at the end of the year.
Year 3
Study of different accelerators
for both applications and ML, including novel accelerators emerging out of this
work; development of custom learning and uncertainty quantification.
Involvement of other teams identified by workshops and other methods with new
applications. Workshop held at the end of the year.
Biographical
Sketches of Key Researchers
Geoffrey Fox received a Ph.D. in Theoretical
Physics from Cambridge University where he was Senior Wrangler. He is a
distinguished professor of Engineering, Computing, and Physics at Indiana
University. He previously held positions
at Caltech, Syracuse University, and Florida State University after postdocs at
the Institute for Advanced Study at Princeton, Lawrence Berkeley Laboratory,
and Peterhouse College, Cambridge. He has supervised the Ph.D. of 72 students
and published around 1300 papers (511 with at least ten citations) in physics
and computing with an hindex of 77 and 35000 citations. He is a Fellow of APS
(Physics) and ACM. His expertise is at the intersection of Big Data and
High-Performance Computing in the area of parallel algorithms and software. He
is experienced at collaborating in and leading multi-institution
multi-disciplinary projects.
Judy Qiu is an Associate Professor of Intelligent
System Engineering and Computer Science at Indiana University. She is a
recipient of NSF CAREER award. Her interests are systems design for AI/Machine
Learning, including distributed/parallel computing and the Internet of Things.
She leads the Intel Parallel Computing Center at IU on high-performance data
analytics.
Kevin Skadron is the Harry Douglas Forsyth
Professor and Chair of Computer Science at the University of Virginia. Skadron
is the recipient of the 2011 ACM SIGARCH Maurice Wilkes Award and a Fellow of
the IEEE and ACM. His interests are in the design of next-generation
microprocessors for speed, energy efficiency, thermal management, and
reliability. He helped found
and serves as director for the UVA Center
for Automata Processing and the SRC/DARPA funded Center for Research on
Intelligent Storage and Processing in Memory (CRISP).
Madhav Marathe is the Director of the Network
Systems Science and Advanced Computing Division at the Biocomplexity Institute
and Initiative at the University of Virginia and a Professor of Computer
Science. He is a fellow of the SIAM, IEEE, ACM, and AAAS. He has published more
than 300 research articles in peer-reviewed journals, conference proceedings,
and books. His areas of expertise include theoretical computer science,
socio-technical systems, high-performance computing, and artificial
intelligence.
Christopher L. Barrett is
Professor and Executive Director of the Biocomplexity Institute and Initiative
at the University of Virginia. He was awarded the 2012–2013 Jubilee
Professorship in Computer Science and Engineering at Chalmers University in
Götebörg, Sweden, and serves in various advisory and collaborative scientific
roles internationally. He has published more than 100 research articles. His
areas of expertise include: Dynamical Networks: Sequential/Graphical Systems,
theoretical and applied research in intelligent systems, translational
research-to-application analytics, and machine intelligence
Shantenu Jha is Chair of the
Center for Data-Driven Discovery (C3D) at DOE’s Brookhaven National Laboratory
and an Associate Professor of Computer Engineering at Rutgers University. He is
the lead of RADICAL-Cybertools which are a suite of middleware building blocks
used to support complex large-scale
science and engineering applications on HPC platforms. He received an NSF
CAREER award.
References
[1] Z. Bei et al., “RFHOC:
a random-Forest approach to auto-tuning Hadoop’s configuration,” IEEE Transactions
on Parallel and Distributed Systems, vol. 27, no. 5, pp. 1470–1483, 2016.
[2] G. Wang, J. Xu, and B. He, “A novel method for tuning
configuration parameters of spark based on machine learning,” in 2016 IEEE 18th
International Conference on High Performance Computing and Communications; IEEE
14th International Conference on Smart City; IEEE 2nd International Conference
on Data Science and Systems (HPCC/SmartCity/DSS), 2016, pp. 586–593.
[3] P. Zhang, J. Fang, T. Tang, C. Yang, and Z. Wang, “Auto-tuning
streamed applications on intel xeon phi,”
in 2018 IEEE International Parallel and Distributed Processing Symposium
(IPDPS), 2018, pp. 515–525.
[4] K. Hou, W. Feng, and S. Che, “Auto-tuning strategies for
parallelizing sparse matrix-vector (spmv)
multiplication on multi-and many-core processors,” in 2017 IEEE International
Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2017, pp.
713–722.
[5] T. L. Falch and A. C. Elster, “Machine learning-based
auto-tuning for enhanced performance portability of OpenCL applications,”
Concurrency and Computation: Practice and Experience, vol. 29, no. 8, p. e4029,
2017.
[6] Z. Wang and M. O’Boyle, “Machine learning in compiler
optimization,” Proceedings of the IEEE, no. 99, pp. 1–23, 2018.
[7] C. Renggli, D. Alistarh, T. Hoefler, and M.
Aghagolzadeh, “Sparcml: High-performance sparse communication for machine
learning,” arXiv preprint arXiv:1802.08021, 2018.
[8] B. Peng et al., “HarpLDA+: Optimizing latent dirichlet
allocation for parallel efficiency,” in 2017 IEEE International Conference on
Big Data (Big Data), 2017, pp. 243–252.
[9] B. Zhang, B. Peng, and J. Qiu, “High performance lda
through collective model communication optimization,” Procedia Computer
Science, vol. 80, pp. 86–97, 2016.
[10] B. ZHANG, B. PENG, and J. QIU, “Parallelizing Big Data
Machine Learning Applications with Model Rotation,” New Frontiers in High
Performance Computing and Big Data, vol. 30, p. 199, 2017.
[11] A. Mathuriya et al., “Scaling grpc tensorflow on 512
nodes of cori supercomputer,” arXiv preprint arXiv:1712.09388, 2017.
[12] Y. Ren et al., “iRDMA: Efficient Use of RDMA in
Distributed Deep Learning Systems,” in 2017 IEEE 19th International Conference
on High Performance Computing and Communications; IEEE 15th International
Conference on Smart City; IEEE 3rd International Conference on Data Science and
Systems (HPCC/SmartCity/DSS), 2017, pp. 231–238.
[13] G. Fox et al., “Learning Everywhere: Pervasive machine learning for effective high-Performance computation,” arXiv preprint arXiv:1902.10810, 2019.
[14] Langshi Chen, Jiayu Li, Ariful Azad, Lei Jiang, Madhav
Marathe, Anil Vullikanti, Andrey Nikolaev, Egor Smirnov, Ruslan Israfilov, Judy
Qiu, A GraphBLAS Approach for Subgraph Counting, arXiv preprint arXiv:1903.04395,
March 11, 2019.
[15] Zhao Zhao, Langshi Chen, Mihai Avram, Meng Li, Guanying
Wang, Ali Butt, Maleq Khan, Madhav Marathe, Judy Qiu, Anil Vullikanti, Finding
and counting tree-like subgraphs using MapReduce, IEEE Transactions on
Multi-Scale Computing Systems, Volume 4, Issues 3, Pages 217-230.
July-September 2018.
[16] Langshi CHEN, Bo PENG, Sabra OSSEN, Anil VULLIKANTI,
Madhav MARATHE, Lei JIANG and JUDY QIU, High-Performance Massive Subgraph
Counting using Pipelined Adaptive-Group Communication. Book Series of “HPC and
Big Data: Convergence and Ecosystem”, Volume 33 and pages 173-197, TopHPC 2017.
Core References
1.
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram
Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe,
Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, "Learning Everywhere:
Pervasive Machine Learning for Effective High-Performance Computation", to be presented at HPBDC 2019,
The 5th IEEE International Workshop on High-Performance Big Data, Deep
Learning, and Cloud Computing in conjunction with The 33rd IEEE International
Parallel and Distributed Processing Symposium (IPDPS 2019) Rio de Janeiro,
Brazil, May 20th, 2019.
2.
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram
Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe,
Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, "Learning Everywhere:
Pervasive Machine Learning for Effective High-Performance Computation:
Application Background", Technical Report
February 16 2019.
Technical Summary
The essential idea is that Machine Learning can dramatically improve large scale computing performance by embedding ML in all aspects of the system execution. This has been demonstrated in several exemplars but not systematically explored from an application or hardware and software systems point of view. We propose an innovative environment with new hardware and software supporting the dynamic flexible interlinking of ML and computation where the latter could either be large scale simulations or data analytics. The environment must support algorithms, hardware and applications. We address the use of ML to optimize configurations and execution modes (MLAutotuning) [1-6], as well for learning the results of all or parts of the computation (MLaroundHPC). At the same time, the system must exhibit HPCforML [7-12] i.e. the machine learning runs fast, to obtain timely results and to minimize overhead for the main computation. All of these new execution modes promise major increases in both performance (inference is many orders of magnitude faster than simulation) and productivity, as they do not require changing existing codes but rather integrate learning with all system aspects, from low-level networking and operating systems to high-level algorithms.
The goal of “learning everywhere” [13] means that we have to make it extremely convenient to add learning to all types of existing software. Our software approach is built around a high-performance environment, “data-linked functions as a service,” that extends dataflow and fully supports the dynamic intermingling of computation and learning and the transfer of data between them. Machine Learning Everywhere also implies extensive research into learning algorithms effective across different uses of MLaroundHPC and their uncertainty quantification.
For the hardware, we need to study appropriate accelerators (both existing accelerators and proposing new ones) and the memory-storage architecture to support the extensive data processing between the learning and computation modules. In particular, we will seek to develop a heterogeneous architecture with accelerators that can be retargeted to support both computation and ML. Because many of these tasks (both the applications and the ML) are extremely data-intensive, it will be of particular importance to design accelerators that minimize data movement overheads, either by pipelining memory accesses and computation, or by tightly coupling computation with the data (via processing-in-memory, die stacking, or other methods of tight physical and architectural integration).
These
software, algorithm, hardware challenges [14-16] need to be motivated and
tested in state of the art applications.
One can expect this approach to have different success and different
challenges in different applications and in this initial study, we hope to get
insight into this using two large-scale network-science problems that are
important in DoD missions. Problems that we will consider include: (i) finding motifs and counting motifs in large
irregular networks, and (ii) simulating
the contagion process. For the contagion simulations, we will build on a long
history in developing scalable simulations where we have already run on
machines with over 700,000 cores. Similarly,
our recent work on computing network motifs represents a factor of 10 improvement over the state of the art methods.
Efficient parallel computing has special difficulties with ML-assisted
computations due to the very different execution times for surrogate (much
smaller) and fully computed results. A further challenge is that heterogeneous architectures
often create a tradeoff between computing where the data currently resides,
using a processor that is not ideally matched to the task, versus moving data
to the most suitable processor. This will need new approaches to load balancing
and new techniques in modeling performance and scaling.
The
“processor suitability” question also motivates reconfigurable architectures
where we will research near-data processor architectures prototyped on FPGAs
with high-bandwidth memory.
Impact: Initial results suggest that effective performance increases from ML-assisted simulations are broadly based and large (105 in one example) and this approach can lead to effective zettascale performance when executed on the upcoming exascale-class systems. So far we have studied molecular simulations (at the nano and biomolecular scales), virtual tissue and cellular simulations, and socio-technical problems such as modeling the spread of disease and epidemics. For these simulations, one can learn dynamic step sizes in space and time and design a principled approach to coarse-graining which appears in the many multi-scale problems we need to study. Examples for data analytics include an influential paper on learning index structures from the data and so outperforming general approaches. Initial results are very promising and our proposed research will allow the application domains to be greatly accelerated and expanded so that these performance gains and impact will cover a broad range of problems; academic, commercial, and national security. This major impact implies that it is critical to immediately start significant activities in Learning Everywhere. Some of the initial studies and experience should open up major new questions on how to use ML and design supporting computer systems that will need deeper study. As well as the core hardware and software challenges, the issues of systematizing coarse-graining, and uncertainty quantification, are just some examples of issues waiting to explode with interest.
Programmatic: The team involves researchers
from Indiana University, Rutgers, and Virginia. The team already has very
effective collaboration built up by multiple joint NSF grants over the last 5
years. Our expertise covers systems hardware,
software, algorithms, and applications and we will use an
algorithmic-systems-hardware codesign process. We will demonstrate initial work
on small clusters exhibiting the key
storage/memory (such as NVMe and Intel Optane or equivalent) and accelerator
(GPU, vector, neuromorphic, FPGA) characteristics. The lead PI will be Geoffrey
Fox from Indiana University, who has experience in the key areas. The software
will be based on an existing high-performance dataflow system Twister2 that was
recently released. The systems work will be covered by Rutgers (Jha) and
Indiana University (Fox, Qiu), and
Virginia University will lead the hardware (Skadron) and the socio-technical
simulations (Marathe, Barrett). Funding requested is $1.5M a year.
Deliverable Timeline
Year 1
Initial software environment running on small customized cluster tested with basic disease applications. Also tested on larger generic clusters with GPUs and with FPGAs, potentially using cloud resources such as Amazon’s F1. Initial research on uncertainty quantification and coarse-graining. Workshop held at the end of the year will identify new applications. Initial application focus on subtree mining and contagion spread.
Year 2
Year one work extended including a larger customized cluster. Initial testing of coarse-graining and uncertainty quantification. Major upgrade to software to enhance usability by a broad community. Applications add the study of tree-like patterns in a general graph. Powerful performance and scaling model. Workshop held at the end of the year.
Year 3
Study of different accelerators for both applications and ML, including novel accelerators emerging out of this work; development of custom learning and uncertainty quantification. Involvement of other teams identified by workshops and other methods with new applications. Workshop held at the end of the year.
Biographical
Sketches of Key Researchers
Geoffrey Fox received a Ph.D. in Theoretical Physics from Cambridge University where he was Senior Wrangler. He is a distinguished professor of Engineering, Computing, and Physics at Indiana University. He previously held positions at Caltech, Syracuse University, and Florida State University after postdocs at the Institute for Advanced Study at Princeton, Lawrence Berkeley Laboratory, and Peterhouse College, Cambridge. He has supervised the Ph.D. of 72 students and published around 1300 papers (511 with at least ten citations) in physics and computing with an hindex of 77 and 35000 citations. He is a Fellow of APS (Physics) and ACM. His expertise is at the intersection of Big Data and High-Performance Computing in the area of parallel algorithms and software. He is experienced at collaborating in and leading multi-institution multi-disciplinary projects.
Judy Qiu is an Associate Professor of Intelligent System Engineering and Computer Science at Indiana University. She is a recipient of NSF CAREER award. Her interests are systems design for AI/Machine Learning, including distributed/parallel computing and the Internet of Things. She leads the Intel Parallel Computing Center at IU on high-performance data analytics.
Kevin Skadron is the Harry Douglas Forsyth
Professor and Chair of Computer Science at the University of Virginia. Skadron
is the recipient of the 2011 ACM SIGARCH Maurice Wilkes Award and a Fellow of
the IEEE and ACM. His interests are in the design of next-generation
microprocessors for speed, energy efficiency, thermal management, and
reliability. He helped found
and serves as director for the UVA Center
for Automata Processing and the SRC/DARPA funded Center for Research on
Intelligent Storage and Processing in Memory (CRISP).
Madhav Marathe is the Director of the Network Systems Science and Advanced Computing Division at the Biocomplexity Institute and Initiative at the University of Virginia and a Professor of Computer Science. He is a fellow of the SIAM, IEEE, ACM, and AAAS. He has published more than 300 research articles in peer-reviewed journals, conference proceedings, and books. His areas of expertise include theoretical computer science, socio-technical systems, high-performance computing, and artificial intelligence.
Christopher L. Barrett is Professor and Executive Director of the Biocomplexity Institute and Initiative at the University of Virginia. He was awarded the 2012–2013 Jubilee Professorship in Computer Science and Engineering at Chalmers University in Götebörg, Sweden, and serves in various advisory and collaborative scientific roles internationally. He has published more than 100 research articles. His areas of expertise include: Dynamical Networks: Sequential/Graphical Systems, theoretical and applied research in intelligent systems, translational research-to-application analytics, and machine intelligence
Shantenu Jha is Chair of the Center for Data-Driven Discovery (C3D) at DOE’s Brookhaven National Laboratory and an Associate Professor of Computer Engineering at Rutgers University. He is the lead of RADICAL-Cybertools which are a suite of middleware building blocks used to support complex large-scale science and engineering applications on HPC platforms. He received an NSF CAREER award.
References
[1] Z. Bei et al., “RFHOC: a random-Forest approach to auto-tuning Hadoop’s configuration,” IEEE Transactions on Parallel and Distributed Systems, vol. 27, no. 5, pp. 1470–1483, 2016.
[2] G. Wang, J. Xu, and B. He, “A novel method for tuning configuration parameters of spark based on machine learning,” in 2016 IEEE 18th International Conference on High Performance Computing and Communications; IEEE 14th International Conference on Smart City; IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), 2016, pp. 586–593.
[3] P. Zhang, J. Fang, T. Tang, C. Yang, and Z. Wang, “Auto-tuning streamed applications on intel xeon phi,” in 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2018, pp. 515–525.
[4] K. Hou, W. Feng, and S. Che, “Auto-tuning strategies for parallelizing sparse matrix-vector (spmv) multiplication on multi-and many-core processors,” in 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2017, pp. 713–722.
[5] T. L. Falch and A. C. Elster, “Machine learning-based auto-tuning for enhanced performance portability of OpenCL applications,” Concurrency and Computation: Practice and Experience, vol. 29, no. 8, p. e4029, 2017.
[6] Z. Wang and M. O’Boyle, “Machine learning in compiler optimization,” Proceedings of the IEEE, no. 99, pp. 1–23, 2018.
[7] C. Renggli, D. Alistarh, T. Hoefler, and M. Aghagolzadeh, “Sparcml: High-performance sparse communication for machine learning,” arXiv preprint arXiv:1802.08021, 2018.
[8] B. Peng et al., “HarpLDA+: Optimizing latent dirichlet allocation for parallel efficiency,” in 2017 IEEE International Conference on Big Data (Big Data), 2017, pp. 243–252.
[9] B. Zhang, B. Peng, and J. Qiu, “High performance lda through collective model communication optimization,” Procedia Computer Science, vol. 80, pp. 86–97, 2016.
[10] B. ZHANG, B. PENG, and J. QIU, “Parallelizing Big Data Machine Learning Applications with Model Rotation,” New Frontiers in High Performance Computing and Big Data, vol. 30, p. 199, 2017.
[11] A. Mathuriya et al., “Scaling grpc tensorflow on 512 nodes of cori supercomputer,” arXiv preprint arXiv:1712.09388, 2017.
[12] Y. Ren et al., “iRDMA: Efficient Use of RDMA in Distributed Deep Learning Systems,” in 2017 IEEE 19th International Conference on High Performance Computing and Communications; IEEE 15th International Conference on Smart City; IEEE 3rd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), 2017, pp. 231–238.
[13] G. Fox et al., “Learning Everywhere: Pervasive machine learning for effective high-Performance computation,” arXiv preprint arXiv:1902.10810, 2019.
[14] Langshi Chen, Jiayu Li, Ariful Azad, Lei Jiang, Madhav Marathe, Anil Vullikanti, Andrey Nikolaev, Egor Smirnov, Ruslan Israfilov, Judy Qiu, A GraphBLAS Approach for Subgraph Counting, arXiv preprint arXiv:1903.04395, March 11, 2019.
[15] Zhao Zhao, Langshi Chen, Mihai Avram, Meng Li, Guanying Wang, Ali Butt, Maleq Khan, Madhav Marathe, Judy Qiu, Anil Vullikanti, Finding and counting tree-like subgraphs using MapReduce, IEEE Transactions on Multi-Scale Computing Systems, Volume 4, Issues 3, Pages 217-230. July-September 2018.
[16] Langshi CHEN, Bo PENG, Sabra OSSEN, Anil VULLIKANTI, Madhav MARATHE, Lei JIANG and JUDY QIU, High-Performance Massive Subgraph Counting using Pipelined Adaptive-Group Communication. Book Series of “HPC and Big Data: Convergence and Ecosystem”, Volume 33 and pages 173-197, TopHPC 2017.